
接到一个需求,要求人工寻找一个菜品不能删除的bug,虽然只有一百多条,但是纯人工一个一个查也太傻了点。作为一个懒癌,当然要整点自动化的东西
分析需求
首先需要登录后台,进到对应url,点击菜品,依次对每个菜品点编辑检查,检查完了点击下一页,查到没得查为止。
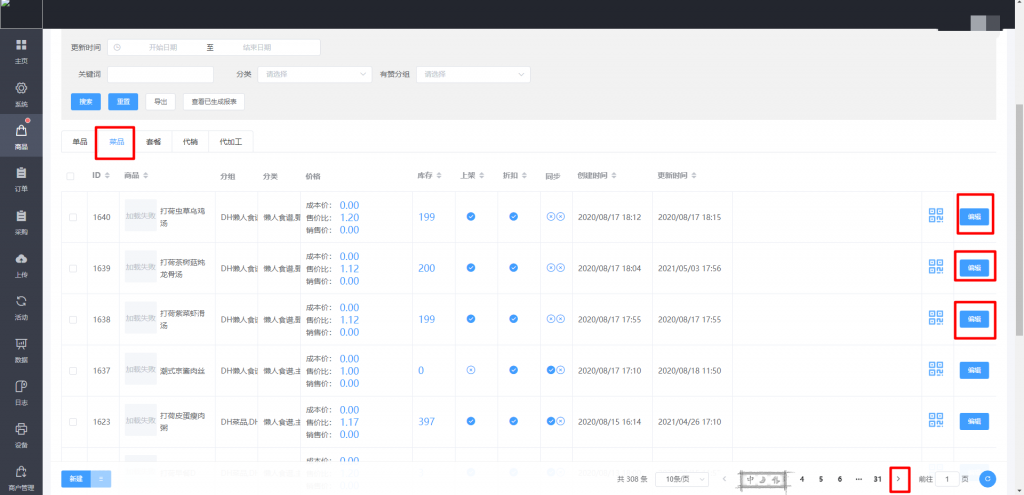
进入每页具体查什么呢,就是检查规格是否能删除
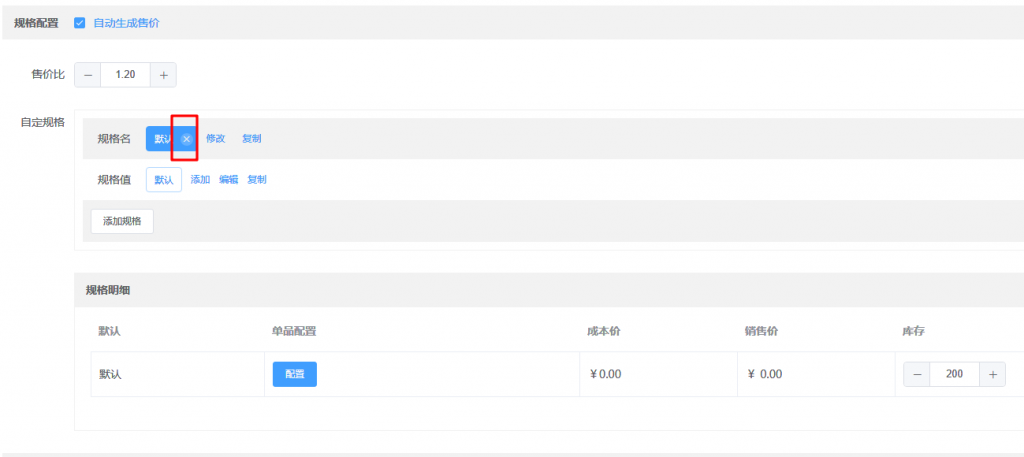
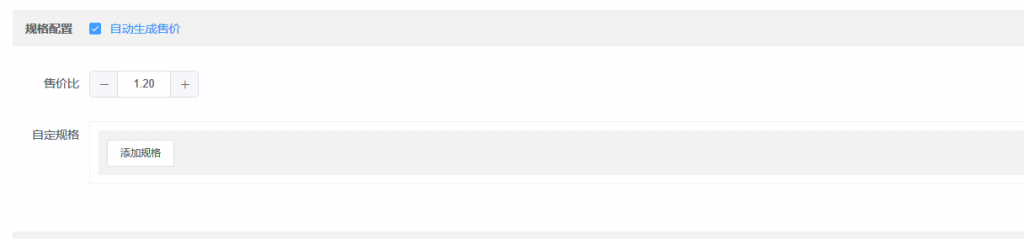
因为技术栈使用了vuejs和element ui,很多东西都是动态渲染的,以上的操作不得不使用selenium
至于是否绑定菜品这个,数据库能查到,就不需要使用selenium,直接连接sql或者api拿数据,而且api没有加密,爬虫党狂喜哈哈哈哈哈
安装
安装分为两部分,一个是安装selenium库,另一个是安装WebDriver驱动
pip安装库
pip install seleniumWebDriver驱动需要根据chrome版本,在selenium官网下载对应版本的,不同版本对应不同版本的浏览器,比如我chrome90版本就得用90版本的WebDriver驱动,不然无法运行。
下载好的WebDriver驱动,解压后有一个exe,放在python目录里。据传还需要设置path,但是我不用设置path也能运行,反正挺玄学,不管了。
首先,当然是打开我们的chrome,也就是初始化,使用1920*1080分辨率打开我们的chrome浏览器访问http://my.lixuqi/backend/
browser = webdriver.Chrome()
browser.set_window_size(1920, 1080)
browser.get('http://my.lixuqi/backend/')接着,加入cookie,绕过登录和该死的验证码,下面的cookies变量是处理上面的cookie用来给requests使用的
cookie = [{"name": "PHPSESSID", "value": "ddgjnb6ma7cmtp50tcqmh24s71"},
{"name": "_identity","value": "%5B300%2C%220zTAd_-ZS4NDkLiRh2sYXsSwfebLHeHh%22%2C86400%5D"},
{"name": "_csrf", "value": "F-WhdZmYuTpMevtSltcQPE9mrAOYRnOb"}]
cookies = {}
for v in range(len(cookie)):
browser.add_cookie(cookie[v])
cookies[cookie[v]["name"]] = cookie[v]["value"]接下来,是我们编写的函数,这个下面会用到
# 判断元素是否存在
def isElementExist(css):
try:
browser.find_element_by_class_name(css)
return True
except:
return False然后就是我们的登录,直奔商品并点击菜品功能,使用了xpath,这个东西很傻瓜的,chrome开发者模式直接复制就可以
# 登录
browser.get('http://my.lixuqi/backend/goods/goods/manage')
# 点击菜品
browser.find_element_by_xpath(
"/html/body/div[1]/div[3]/div/div[1]/div[3]/div[1]/div[2]/div[2]/div[1]/div/div/div/div[2]").click()然后写了一个读log的功能,自动从上次停止的地方继续工作
# 设置log
f = "webtest_log.txt"
# 读取log,从上次停止的地方继续工作
print("读取log(2/5)")
with open(f, "r", encoding='utf-8') as file:
try:
j = json.loads(file.read())
successlist = j["successlist"]
errorlist = j["errorlist"]
except:
print("读取log失败")
file.close()接下来就是老本行爬数据了,几层循环,最后得到一个所有绑定了套餐的菜品id的list,geolist
# 爬取api
print("爬取api(3/5)")
geolist = []
r = requests.get("http://my.lixuqi/backend/goods/goods/list-data?page=1&type=3&keyword=&state=&category_id=&tag_id=&auto_create_price=&youzan_join_level_discount=&get_data_syn=&youzan_auto_syn=&updated_price=&changeStock=0&order=desc&by=id&size=100",cookies=cookies)
j = json.loads(r.text)
for a in range(len(j["rows"])):
url = 'http://my.lixuqi/backend/goods/goods/save-form-data?id=' + str(j["rows"][a]["id"]) + '&type=3'
r = requests.get(url,cookies=cookies)
r.encoding = "utf-8"
j1 = json.loads(r.text)
for b in range(len(j1['skuDetailForm'])):
for c in range(len(j1['skuDetailForm'][b]['dpc'])):
geolist.append(j1['skuDetailForm'][b]['dpc'][c]['id'])
# geolist输出
# ['1402', '1326', '1356', '1411', '1501', '1283', '1390', '1416', '915', '1407', '1405', '1340', '1322', '1390', '1413', '1432', '1365', '1343', '1331', '1394', '1356', '1411', '1501', '1283', '767', '768', '769', '762', '761', '760', '757', '758', '759', '739', '754', '742', '756', '751', '749', '750', '752', '746', '747', '738']
最后就是干正事,首先循环113次,因为一共有114页。然后使用类似yii,thinkphp那一套链式数据库查询。找一个tobdy下的所有button(不要眼花,后一个find_elements的elements多出了一个s。是查all的)
接下来的browser.execute_script是执行js脚本的,就是一个滚动到页面底部的功能(var q=document.documentElement.scrollTop=10000;改成var q=document.documentElement.scrollTop=0;的话可以滚回页面顶部。)
接下来的第一个for主要判断这个页面最后一个按钮点击打开的新窗口url是不是已经存在log的成功list中,如果是的话直接跳转下一页
如果不是,挨个按钮从头开始点,点完打开的新窗口,首先把browser切换到新窗口,然后判断是否存在成功list里,如果是,直接跳过。
如果不是,会尝试下滑一定值的滚动条,然后尝试点击xpath钦定的元素,接着判断点击完某个元素是否失踪,并结合geolist是否存在该值,得出结果并写进log
最后就是写log的代码,每循环一次覆盖写一遍,避免跑一半中断导致数据丢失。
for h in range(113):
edit = browser.find_element_by_tag_name("tbody").find_elements_by_tag_name("button")
browser.execute_script("var q=document.documentElement.scrollTop=10000;", edit[-1])
edit[-1].click()
sleep(2)
handles = browser.window_handles
ifurl = ""
# 对窗口进行遍历
staus = ""
for newhandle in handles:
# 筛选新打开的窗口B
if newhandle != handle:
# 切换到新打开的窗口B
browser.switch_to_window(newhandle)
ifurl = browser.current_url
browser.close()
browser.switch_to_window(handles[0])
if re.search("\d+",ifurl).group() in successlist:
pass
else:
browser.execute_script("var q=document.documentElement.scrollTop=0;", edit[-1])
for i in range(len(edit)):
sleep(6)
browser.execute_script("window.scrollBy(0," + str(num) + ")", edit[i])
edit[i].click()
sleep(2)
handles = browser.window_handles
# 对窗口进行遍历
staus = ""
for newhandle in handles:
# 筛选新打开的窗口B
if newhandle != handle:
# 切换到新打开的窗口B
browser.switch_to_window(newhandle)
print(browser.current_url)
if browser.current_url not in successlist:
sleep(4)
ed = browser.find_element_by_xpath('/html/body/div/div[3]/div/div[1]/div[3]/form/div[1]/div[13]/div[1]/div/div/table/tr[1]/td[2]/span/i')
browser.execute_script("window.scrollBy(0,1000)", ed)
ed.click()
sleep(1)
# 判断 goods-attr-assign-row-label 是否存在
ifurl = browser.current_url
if isElementExist("goods-attr-assign-row-label"):
if re.search("\d+",ifurl).group() in geolist:
successlist.append(browser.current_url)
staus = "成功,虽然不能删除但是有绑定"
else:
errorlist.append(browser.current_url)
staus = "错误,删除失败"
else:
if re.search("\d+",ifurl).group() in geolist:
errorlist.append(browser.current_url)
staus = "错误,删除成功但是有绑定"
else:
successlist.append(browser.current_url)
staus = "成功,可以删除"
sleep(2)
else:
print("检测到log爬过,已跳过")
browser.close()
browser.switch_to_window(handles[0])
print("已爬第" + str(h+1) + "页" + str(i+1) + "个" + " - 结果:" + staus)
with open(f, "w", encoding='utf-8') as file:
file.write(json.dumps(
{"successlist": successlist, "errorlist": errorlist}))
file.close()
nextpage = browser.find_element_by_class_name("btn-next").click()
sleep(2)
print("收工(5/5)")最终代码
from selenium import webdriver
from time import sleep
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
import requests
import re
# 初始化
print("初始化(1/5)")
browser = webdriver.Chrome()
browser.set_window_size(1920, 1080)
browser.get('http://my.lixuqi/backend/')
# 加入cookie
cookie = [{"name": "PHPSESSID", "value": "ddgjnb6ma7cmtp50tcqmh24s71"},
{"name": "_identity","value": "%5B300%2C%220zTAd_-ZS4NDkLiRh2sYXsSwfebLHeHh%22%2C86400%5D"},
{"name": "_csrf", "value": "F-WhdZmYuTpMevtSltcQPE9mrAOYRnOb"}]
cookies = {}
for v in range(len(cookie)):
browser.add_cookie(cookie[v])
cookies[cookie[v]["name"]] = cookie[v]["value"]
# 判断元素是否存在
def isElementExist(css):
try:
browser.find_element_by_class_name(css)
return True
except:
return False
# 设置log
f = "webtest_log.txt"
# 登录
browser.get('http://my.lixuqi/backend/goods/goods/manage')
# 点击菜品
browser.find_element_by_xpath(
"/html/body/div[1]/div[3]/div/div[1]/div[3]/div[1]/div[2]/div[2]/div[1]/div/div/div/div[2]").click()
sleep(10)
# WebDriverWait(browser, 10,0.5).until(EC.presence_of_element_located((By.ID,"tr")))
handle = browser.current_window_handle
num = 100
successlist = []
errorlist = []
# 读取log,从上次停止的地方继续工作
print("读取log(2/5)")
with open(f, "r", encoding='utf-8') as file:
try:
j = json.loads(file.read())
successlist = j["successlist"]
errorlist = j["errorlist"]
except:
print("读取log失败")
file.close()
# 爬取api
print("爬取api(3/5)")
geolist = []
r = requests.get("http://my.lixuqi/backend/goods/goods/list-data?page=1&type=3&keyword=&state=&category_id=&tag_id=&auto_create_price=&youzan_join_level_discount=&get_data_syn=&youzan_auto_syn=&updated_price=&changeStock=0&order=desc&by=id&size=100",cookies=cookies)
j = json.loads(r.text)
for a in range(len(j["rows"])):
url = 'http://my.lixuqi/backend/goods/goods/save-form-data?id=' + str(j["rows"][a]["id"]) + '&type=3'
r = requests.get(url,cookies=cookies)
r.encoding = "utf-8"
j1 = json.loads(r.text)
for b in range(len(j1['skuDetailForm'])):
for c in range(len(j1['skuDetailForm'][b]['dpc'])):
geolist.append(j1['skuDetailForm'][b]['dpc'][c]['id'])
print(geolist)
print("工作(4/5)")
for h in range(113):
edit = browser.find_element_by_tag_name("tbody").find_elements_by_tag_name("button")
browser.execute_script("var q=document.documentElement.scrollTop=10000;", edit[-1])
edit[-1].click()
sleep(2)
handles = browser.window_handles
ifurl = ""
# 对窗口进行遍历
staus = ""
for newhandle in handles:
# 筛选新打开的窗口B
if newhandle != handle:
# 切换到新打开的窗口B
browser.switch_to_window(newhandle)
ifurl = browser.current_url
browser.close()
browser.switch_to_window(handles[0])
if re.search("\d+",ifurl).group() in successlist:
pass
else:
browser.execute_script("var q=document.documentElement.scrollTop=0;", edit[-1])
for i in range(len(edit)):
sleep(6)
browser.execute_script("window.scrollBy(0," + str(num) + ")", edit[i])
edit[i].click()
sleep(2)
handles = browser.window_handles
# 对窗口进行遍历
staus = ""
for newhandle in handles:
# 筛选新打开的窗口B
if newhandle != handle:
# 切换到新打开的窗口B
browser.switch_to_window(newhandle)
print(browser.current_url)
if browser.current_url not in successlist:
sleep(4)
ed = browser.find_element_by_xpath('/html/body/div/div[3]/div/div[1]/div[3]/form/div[1]/div[13]/div[1]/div/div/table/tr[1]/td[2]/span/i')
browser.execute_script("window.scrollBy(0,1000)", ed)
ed.click()
sleep(1)
# 判断 goods-attr-assign-row-label 是否存在
ifurl = browser.current_url
if isElementExist("goods-attr-assign-row-label"):
if re.search("\d+",ifurl).group() in geolist:
successlist.append(browser.current_url)
staus = "成功,虽然不能删除但是有绑定"
else:
errorlist.append(browser.current_url)
staus = "错误,删除失败"
else:
if re.search("\d+",ifurl).group() in geolist:
errorlist.append(browser.current_url)
staus = "错误,删除成功但是有绑定"
else:
successlist.append(browser.current_url)
staus = "成功,可以删除"
sleep(2)
else:
print("检测到log爬过,已跳过")
browser.close()
browser.switch_to_window(handles[0])
print("已爬第" + str(h+1) + "页" + str(i+1) + "个" + " - 结果:" + staus)
with open(f, "w", encoding='utf-8') as file:
file.write(json.dumps(
{"successlist": successlist, "errorlist": errorlist}))
file.close()
nextpage = browser.find_element_by_class_name("btn-next").click()
sleep(2)
print("收工(5/5)")
#
# 'goods/goods/manage'
# driver.find_element(By.ID, "tab-2").click()

Comments | NOTHING