
前言
偶然发现以前做过的作业,发上来供后来人参考参考。
文档最后更新于 2020-12 可能和现在有出入
本hadoop搭建教程 为 云计算导论(第2版)(大数据与人工智能技术丛书)
(ps:这本书长这个样)

第10章的部分内容。当然,书里的内容很简略,而且还埋着不少坑。
这篇博文,既是作业,也是保姆级教程,应该算是非常详细了吧。
如果你们学校也用这本书要做hadoop作业,可以参考本教程。
step 0. 实验环境
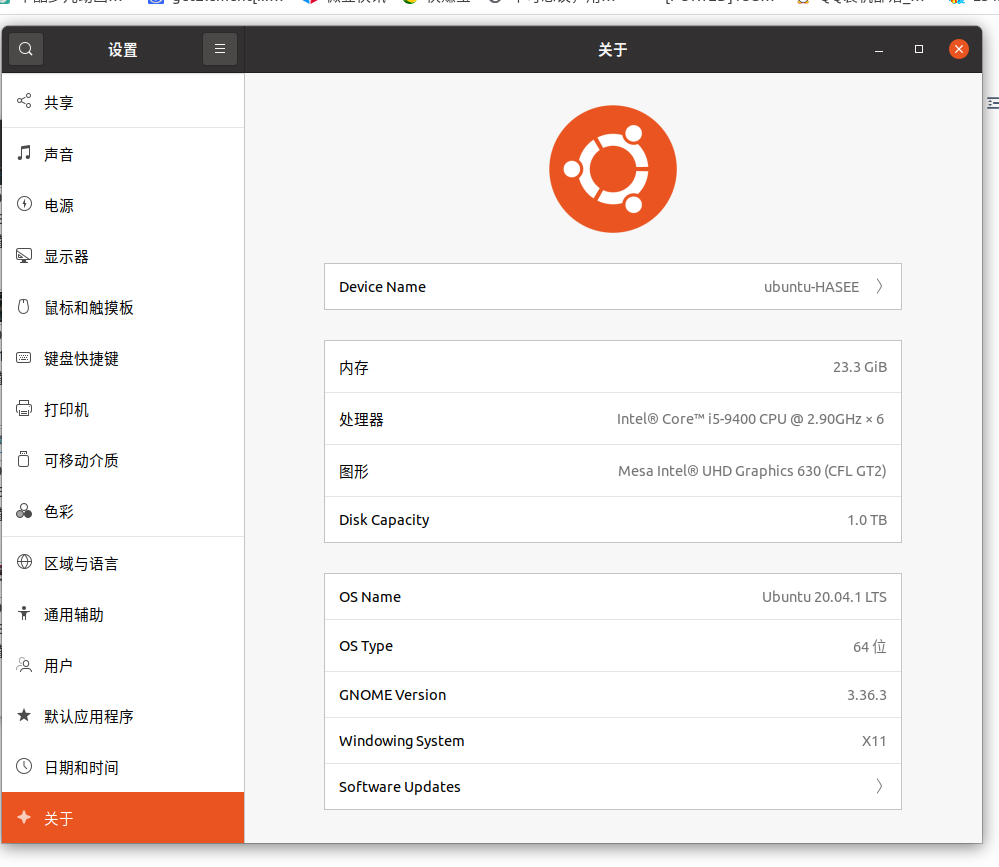
- 正常的笔记本一台
- 系统:ubuntu 20.04.1 LTS
- CPU:嘤特尔 酷睿 i5-9400(第九代)@ 2.9Ghz x 6核处理器
- 运行内存:24G
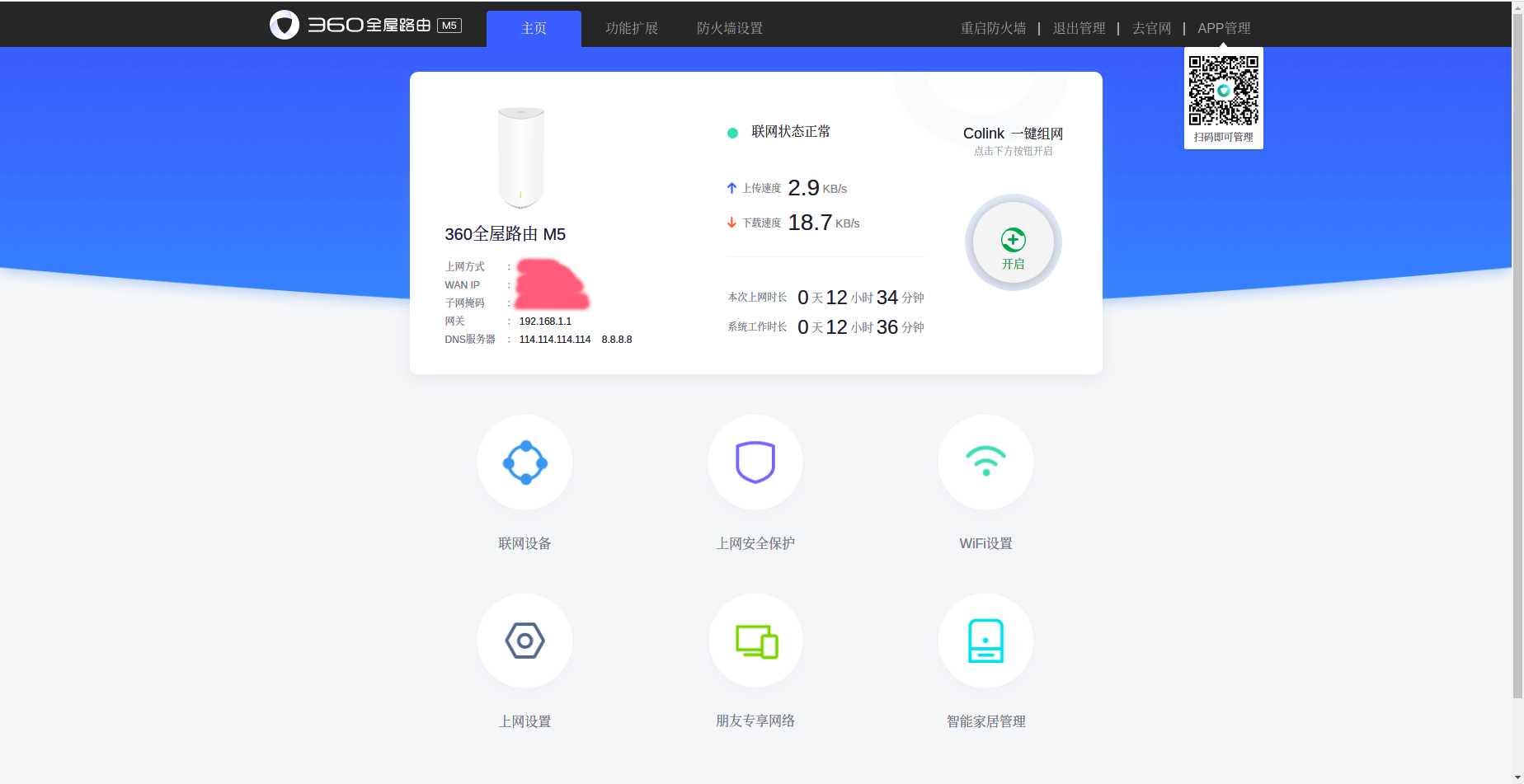
- 可正常连接互联网的路由器一台
- 网关:192.168.0.1
- 分配地址:192.168.0.2 ~ 192.168.0.254
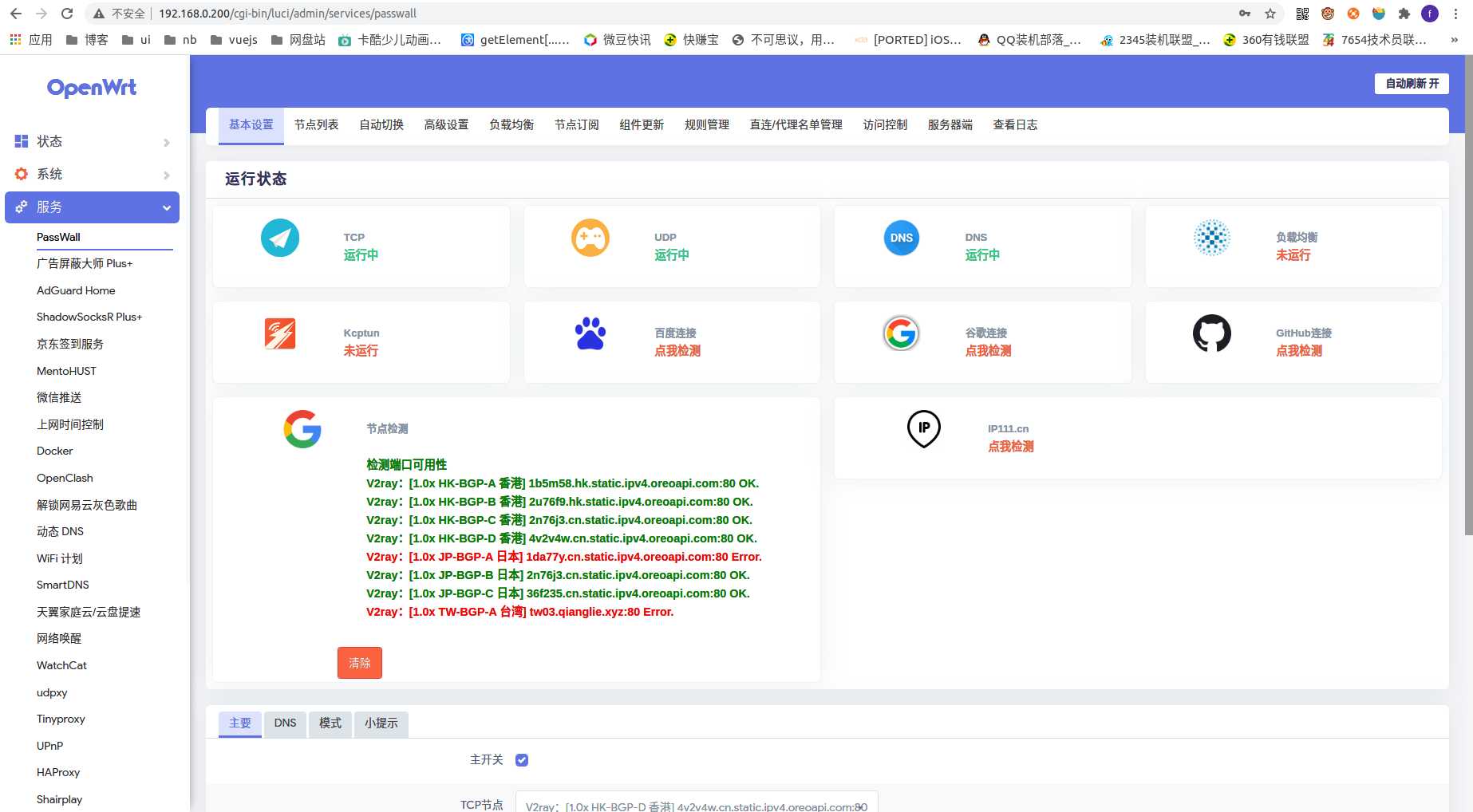
- 可加速外网访问的openwrt x86旁路由一台,用于加速github等访问(通过x86虚拟机运行于nas服务器)
- 网关 :192.168.0.200
- 分配地址:不分配(关闭dhcp服务)
- (可选)开启smb服务的nas服务器一台,用于虚拟机之间的文件共享
- 系统:
黑群晖 - 运存:
4G
- 系统:
- (可选)docker部署的私有为知笔记服务,用于编写这份文档(运行于nas服务器)
step 1.构建虚拟机网络(对应课本10.5.2)
1.1 VirtualBox的安装和配置
建议配置:
| 虚拟机 | hostname | 处理器 | 内存 | 硬盘 |
|---|---|---|---|---|
| ubuntu1 | master | 四核 | 2G | 40G |
| ubuntu2 | slave1 | 双核 | 2G | 40G |
| ubuntu3 | slave2 | 双核 | 2G | 40G |
注意注意注意!这里先建立一台虚拟机,等配置好后再复制成三台。不要建立三台!
注意注意注意!这里先建立一台虚拟机,等配置好后再复制成三台。不要建立三台!
注意注意注意!这里先建立一台虚拟机,等配置好后再复制成三台。不要建立三台!
略
1.2 Ubuntu网络配置
1.2.1 配置网络
三台虚拟机我设想的IP分配:
警告!每个人的环境不一样,请根据你的路由器的网段来配置,不要照抄
因为我的路由器网关是192.168.0.1
路由器下的连接设备分配的ip为192.168.0.1 - 192.168.0.254
而且,我的虚拟机的网络为桥接模式
所以,我的虚拟机分配的ip是192.168.0.x
| 虚拟机 | hostname | ip |
|---|---|---|
| ubuntu1 | master | 192.168.0.129 |
| ubuntu2 | slave1 | 192.168.0.130 |
| ubuntu3 | slave2 | 192.168.0.131 |
根据以上表格,我们来配置主机网络
选择有线设置

点击小齿轮
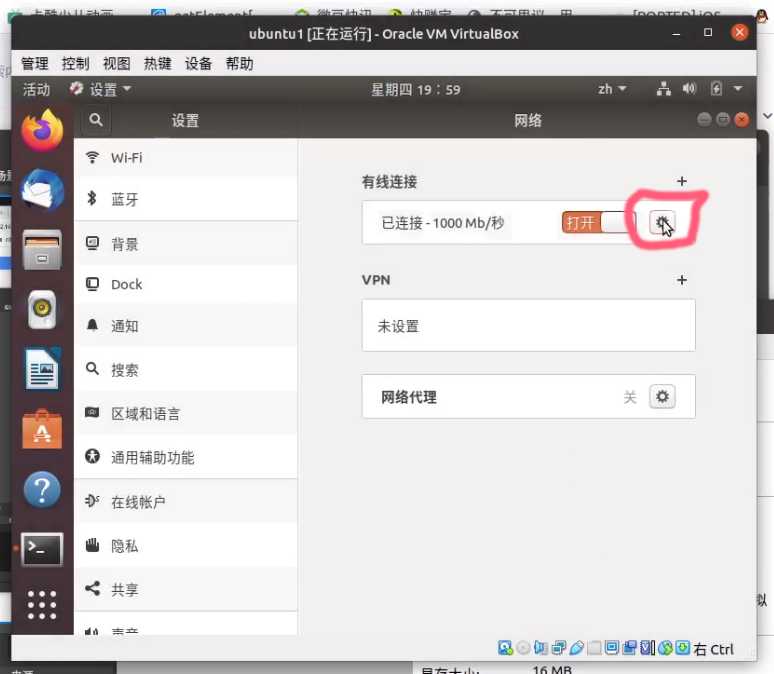
选择 IPv4 - 手动 - 地址
地址填写 192.168.0.129
子网掩码 255.255.255.0
网关填写 192.168.0.200 是因为我要让数据走旁路由处理(国外下载加速)
毕竟待会ubuntu下载东西可能需要下载到国外的资源
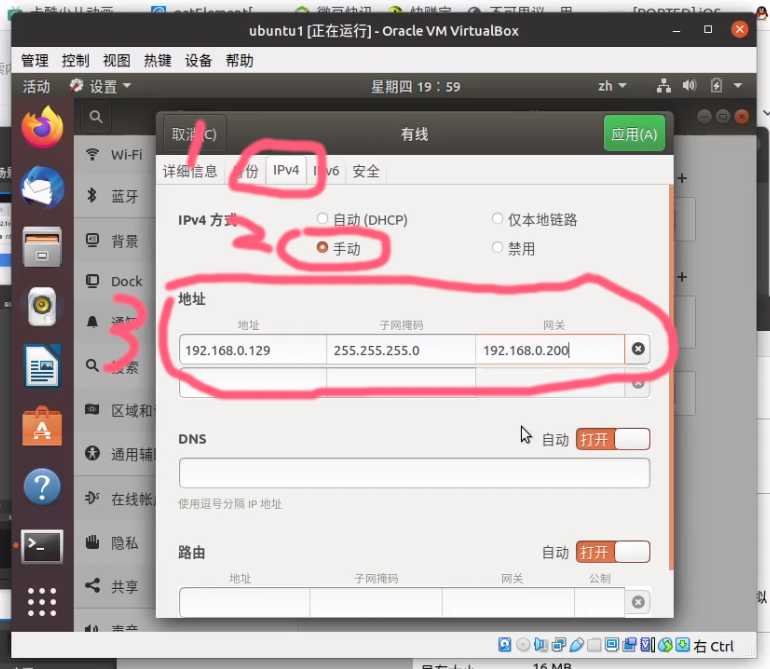
如果你没有旁路由就不要学我,老老实实的填写 192.168.0.1
使用旁路由还需要把 dns 改为 192.168.0.200

虚拟机内打开任意一个国外网站,可以正常打开,说明已经成功连接旁路由,加速国外可以正常使用
1.2.2 修改主机名(hostname)
sudo gedit /etc/hostname
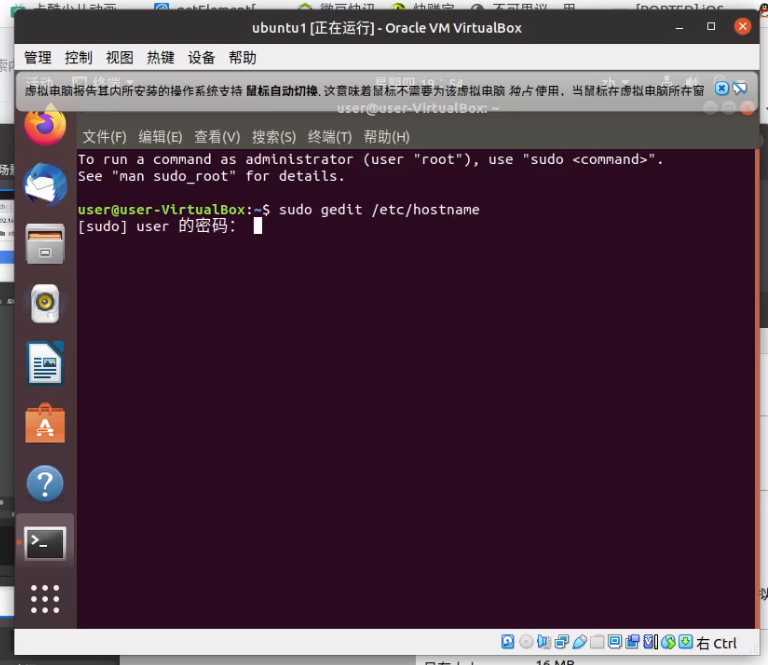
这里我们把内容改为master
1.2.3 修改hosts
sudo gedit /etc/hosts
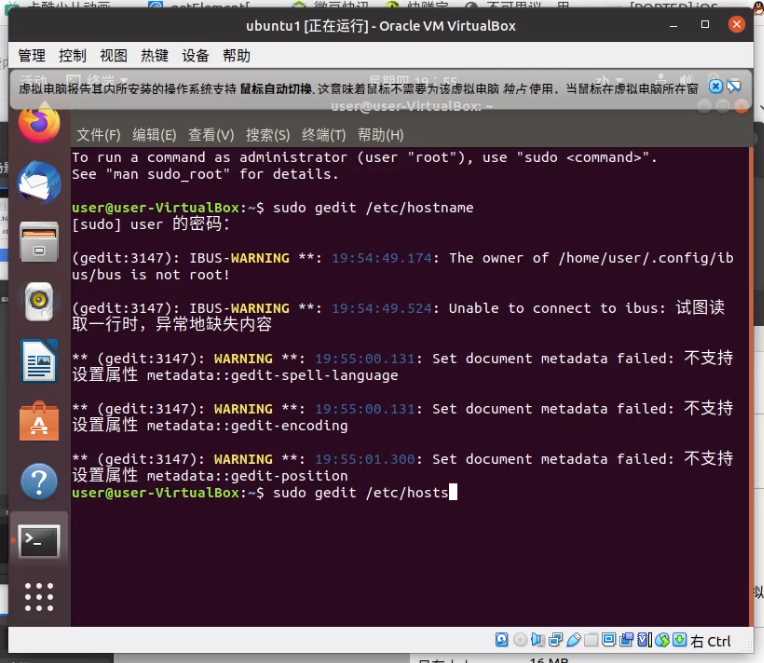
在 127.0.0.1 行后插入
192.168.0.129 master
192.168.0.130 slave1
192.168.0.131 slave2

1.2.4 关闭防火墙
执行
sudo ufw status
如果显示不活动,不用管。如果显示活动,就需要关闭
1.3 安装hadoop前的准备
1.3.1 安装必要软件包
sudo apt install gcc net-tools vim openssh-server
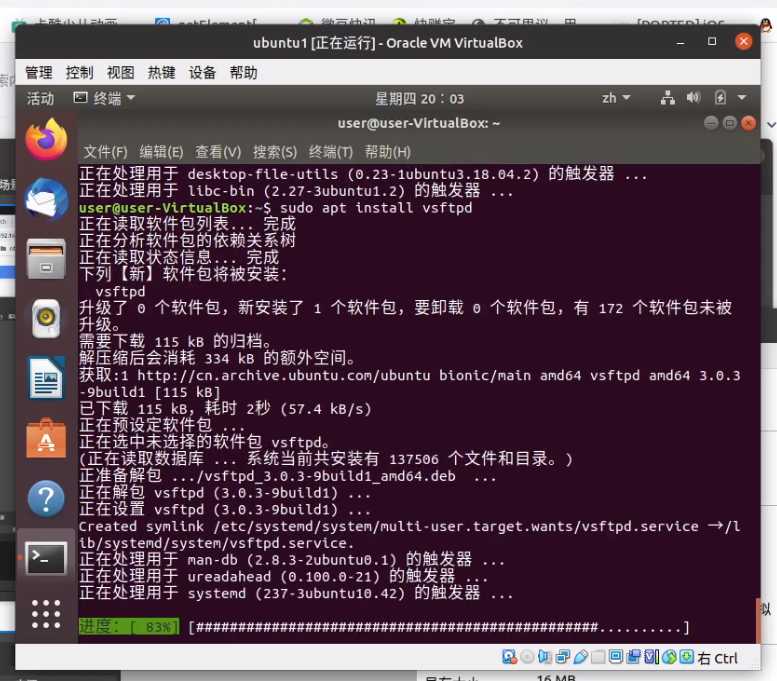
1.3.2 安装JDK
下载Jdk(略)
把 ~/jdk-8u271-linux-x64.tar.gz 放在 家 目录
在 /usr/loacl/ 下打开终端 执行
sudo cp ~/jdk-8u271-linux-x64.tar.gz ~/jdk-8u271-linux-x64.tar.gz
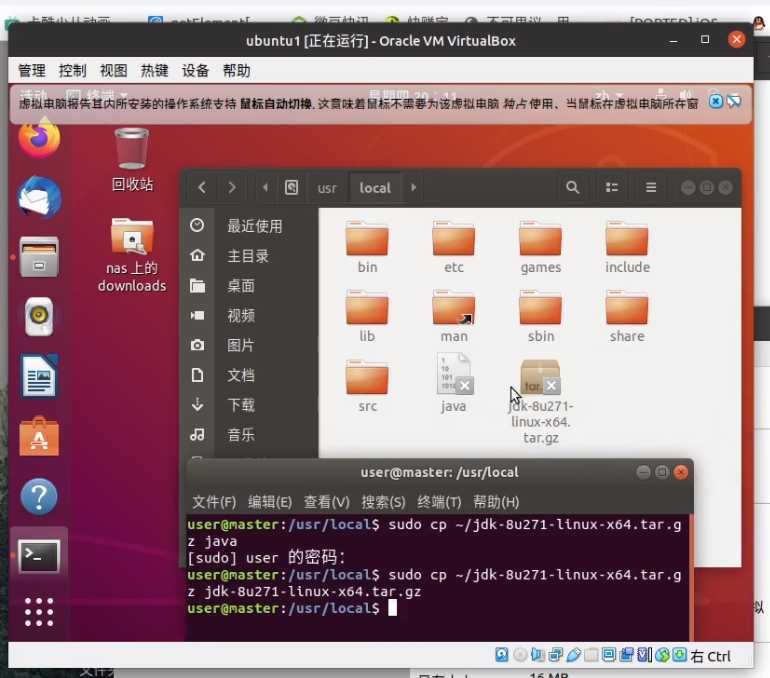
在 /usr/loacl/ 下解压 tar.gz
sudo tar -zxvf jdk-8u271-linux-x64.tar.gz

解压成功后会获得一个 jdk1.8.0_271 的文件夹 ,我们要将它改名为 java,在 /usr/loacl/ 下执行
sudo mv jdk1.8.0_271/ java
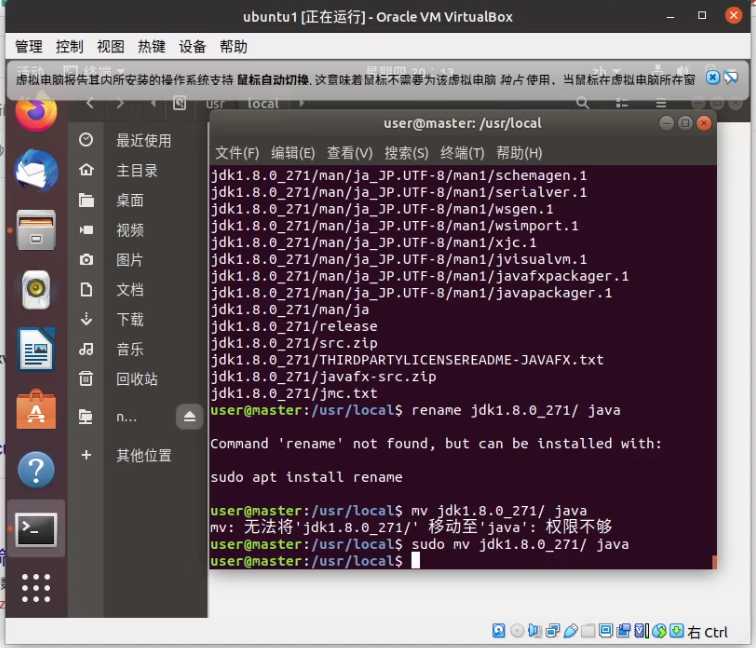
最后,收尾工作,修改 /etc/profile 文件
sudo gedit /etc/profile
在文档末尾插入如下代码
#set java&hadoop environment
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:${JAVA_HOME}:$PATH
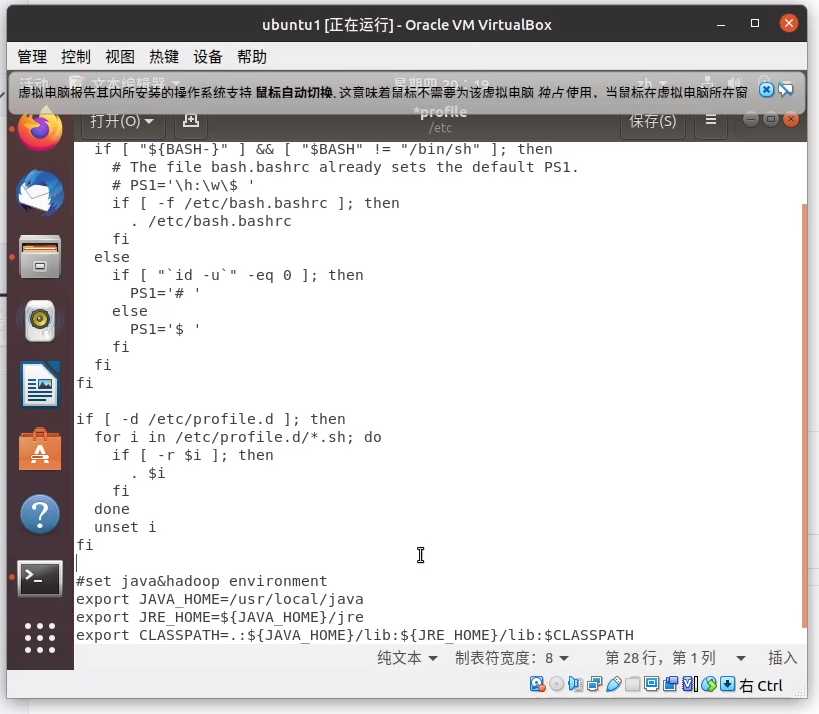
保存,执行如下命令让文档生效
sudo source /etc/profile

step 2.大数据环境安装(对应课本10.5.3)
2.1 克隆两台虚拟机slave1和slave2
控制 - 复制虚拟机
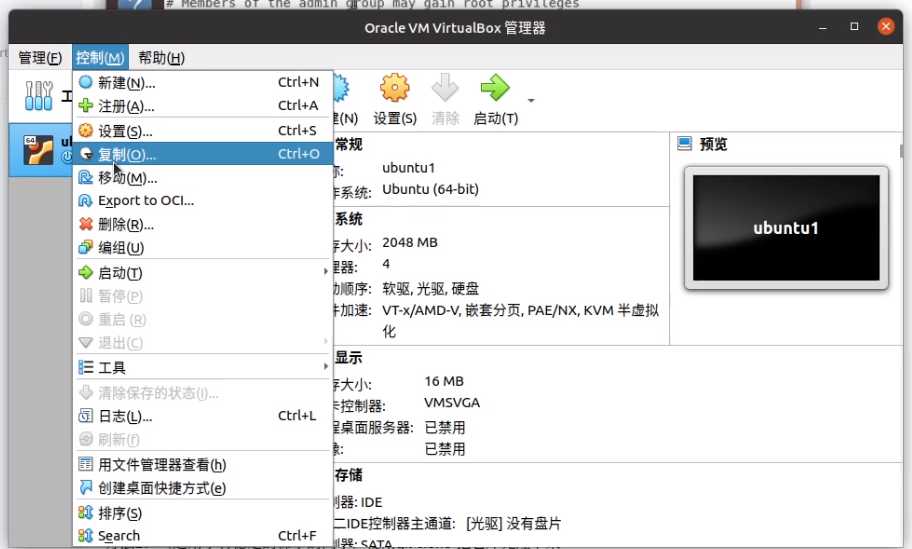
一定要选择为所有网卡重新生成MAC地址!!
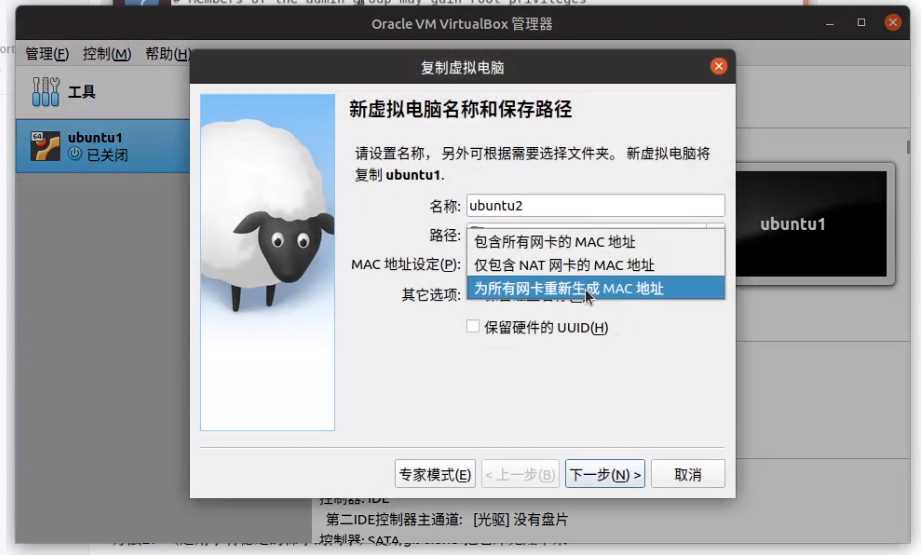
等它克隆,我们喝口茶先~
两台虚拟机克隆完了进 设置 - 网络 - 网卡1 - 高级 - 生成随机mac的按钮多戳几下,这样才保险
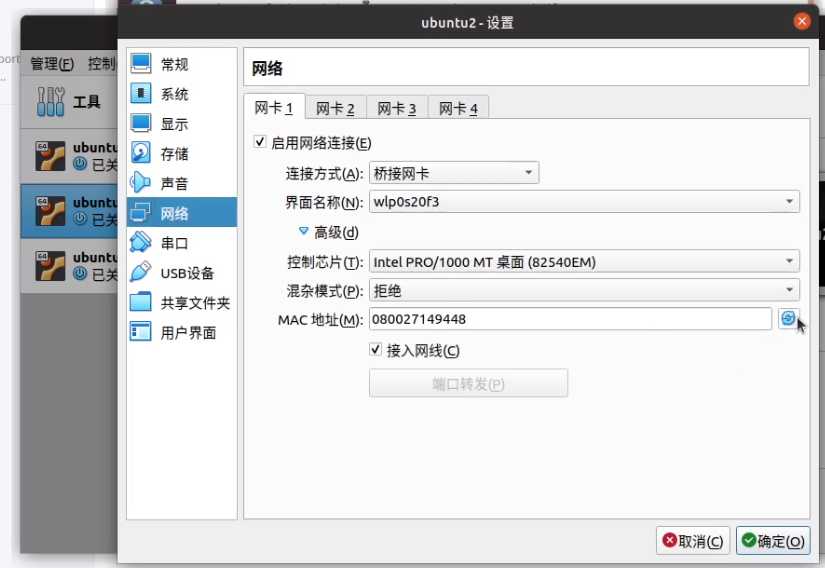
启动新克隆的两台虚拟机,配置网络,ipv4的ip分别为
slave1 = > 192.168.0.130
slave2 = > 192.168.0.131
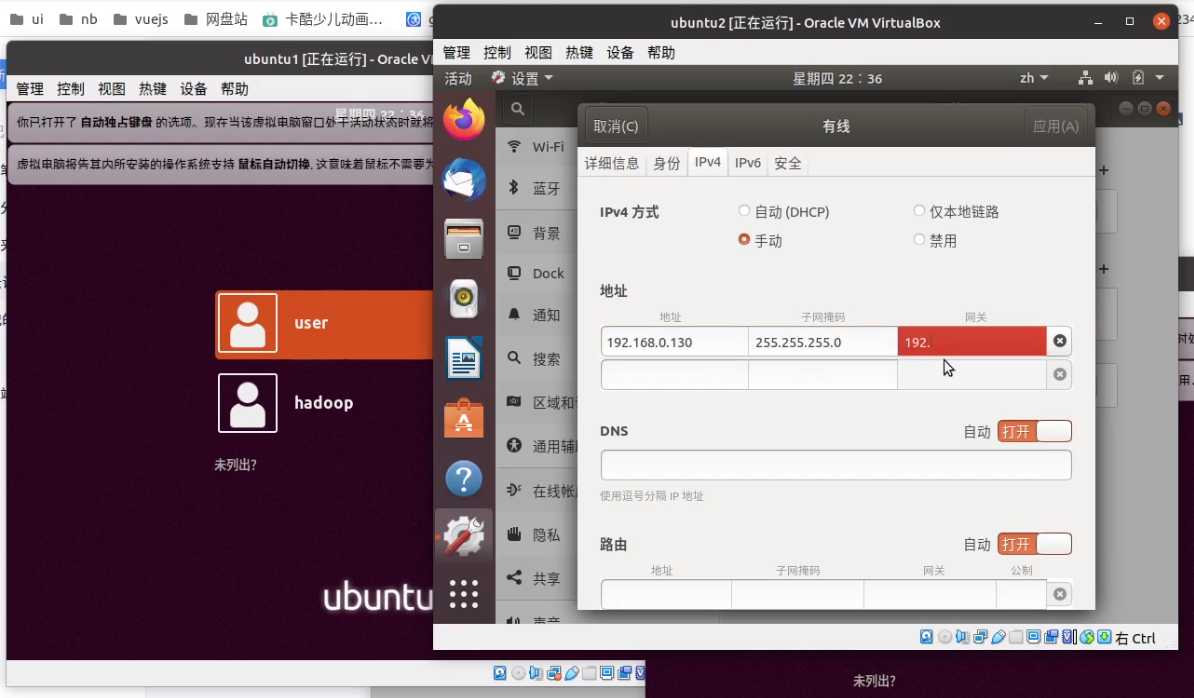
记得修改hostname

2.2 配置SSH
这一步很重要,请务必按步骤认真做,不然会导致后面hadoop
start-all.sh开启失败
slave1,slave2虚拟机执行
ssh-keygen -t rsa -P ""

生成 ssh rsa 密钥
slave1 再执行
scp /home/user/.ssh/id_rsa.pub user@master:/home/user/.ssh/slave1_id_rsa.pub
slave2再执行
scp /home/user/.ssh/id_rsa.pub user@master:/home/user/.ssh/slave2_id_rsa.pub

把 slave1 和 slave2 的 ssh 密钥发到 master 后,在 master 虚拟机执行
ssh-keygen -t rsa -P ""
检查 master 的 家 目录下的.ssh里面有没有 id_rsa.pub 和 slave1_id_rsa.pub 和 slave2_id_rsa.pub
有的哈就可以合并密钥来免密登陆了
master虚拟机在.ssh目录下执行
cat *pub >> authorized_keys
scp authorized_keys user@slave1:/home/user/.ssh/authorized_keys
scp authorized_keys user@slave2:/home/user/.ssh/authorized_keys

然后在 slave1 和 slave2 上分别执行
sudo chmod 644 authorized_keys
最后,验证在master主机能否不输密码ssh到其他主机
分别执行
ssh 'user@slave1'
和
ssh 'user@slave2'
如果在yes之后可以免密码登录,就是成功
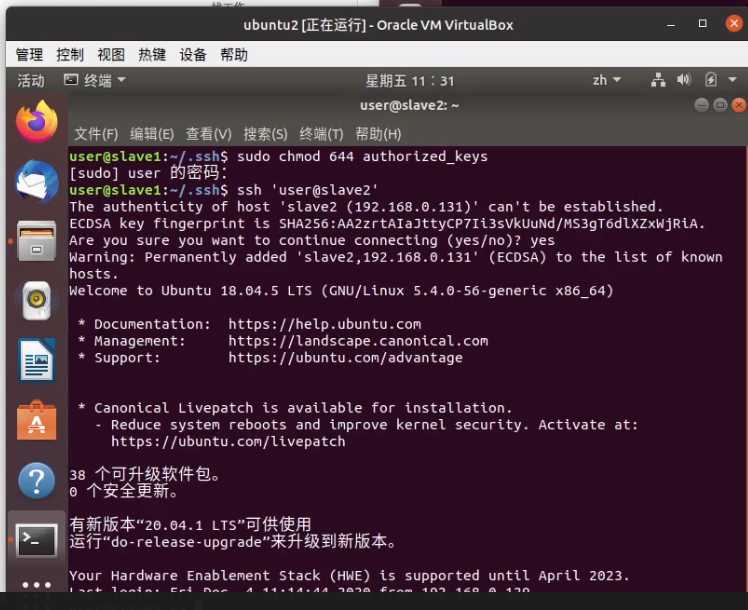
2.3 正式安装Hadoop
首先,把下载的hadoop弄到你的 家
家 目录下,执行解压命令
tar -xvf hadoop-2.10.1.tar.gz
复制到 /usr/ 里
sudo cp hadoop-2.10.1 /usr/hadoop
执行
sudo gedit /etc/profile
在之前java的后面插入如下代码
export HADOOP_HOME=/usr/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LTB_NAVTIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
最后执行source让修改生效
sudo source /etc/profile


2.4 配置hadoop
依次修改 /usr/hadoop/etc/hadoop/ 下的
hadoop-env.sh,把JAVA_HOME写成绝对地址,如下
export JAVA_HOME=/usr/local/java

修改slaves内容为
master
slave1
slave2
core-site.xml 的<configuration></configuration>中插入
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop临时目录,自行创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
hdfs-site.xml 的<configuration></configuration>中插入
<!-- 设置dfs副本数,不设置默认是3个 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置secondname的端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
mapred-site.xml 的<configuration></configuration>中插入
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
yarn-site.xml 的<configuration></configuration>中插入
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>${yarn.log.dir}/userlogs</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
以上文件修改完之后,复制整个修改后的hadoop文件夹,到其余没有配置的虚拟机上,三台虚拟机都要配置好
配置好之后,家 目录执行指令格式化HDFS文件系统(不要格式化多次,不然要多走弯路)
hdfs namenode -format
启动hadoop集群
start-all.sh
检查是否正常启动
hdfs dfsadmin -report
step 3.大数据环境分析(对应课本10.5.4)
3.1 日志分析
3.1.1 下载详细完整代码和数据
- 方法1:(适用于有稳定的梯子的同学)使用git clone 把仓库克隆下来
在家目录下右键打开终端,运行
git clone https://github.com/bdintro/bdintro.git
稍等片刻,你的家里有有一个叫bdintro的文件夹,里面装满了你想要的东西
如果你的加速访问github的梯子不稳定的话,可能会出现下一半报错终止下载的情况,这时我们可以手动在github网站下载解压
- 方法2:在github网站下载
浏览器打开
https://github.com/bdintro/bdintro
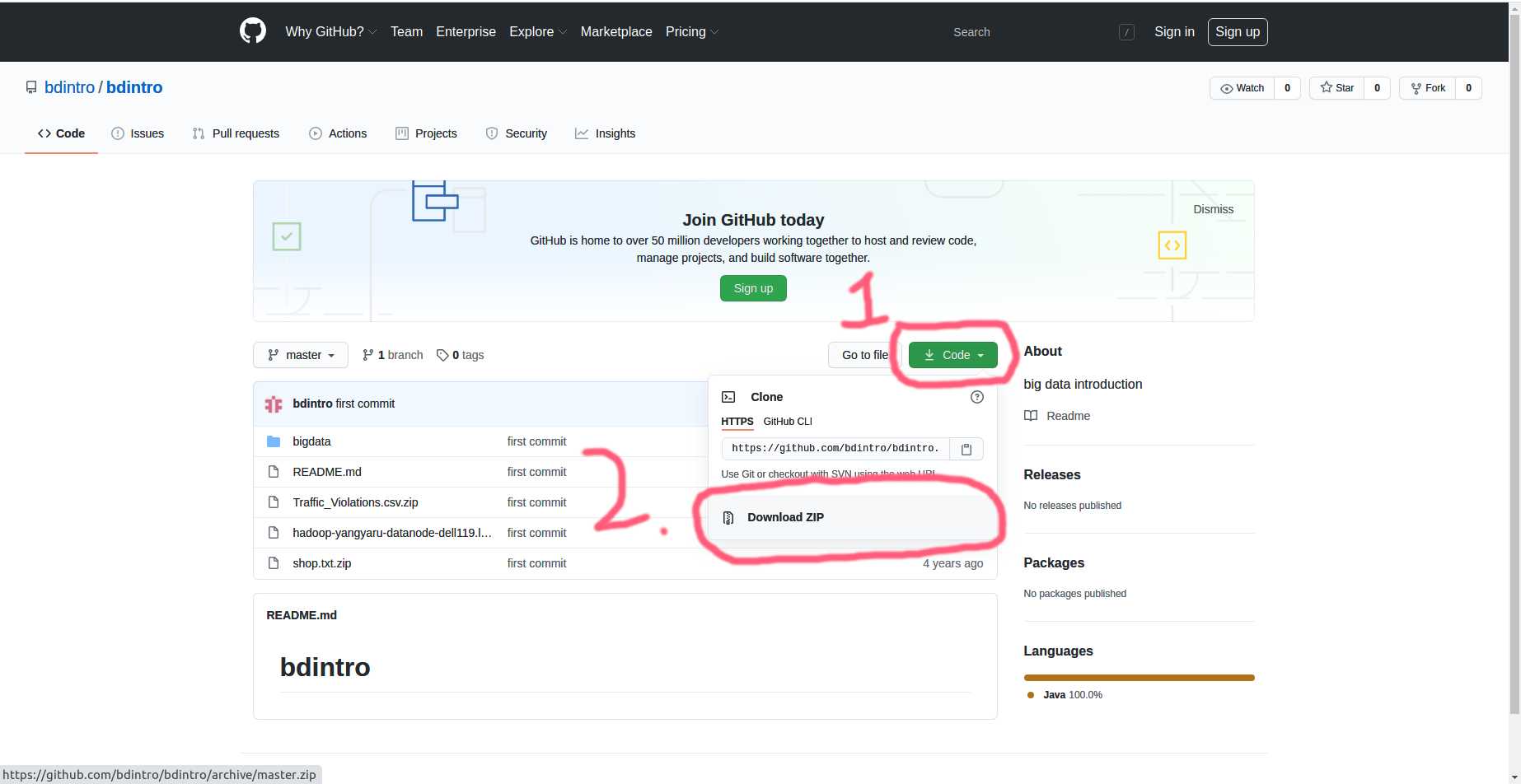
按上图的顺序,依次点击下载bdintro
3.1.2 mvn package编译Jar包
正确执行3.1.1步骤后会得到以下文件
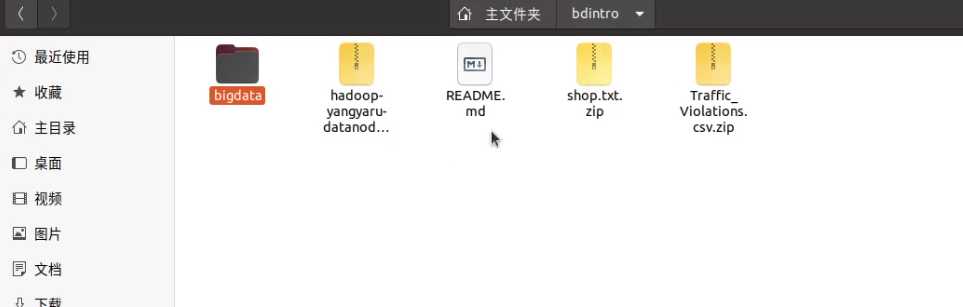
在正式使用mvn package编译Jar包之前,我们需要安装依赖,不然,会提示
command 'mvn' not found
打开终端,执行
sudo apt install maven
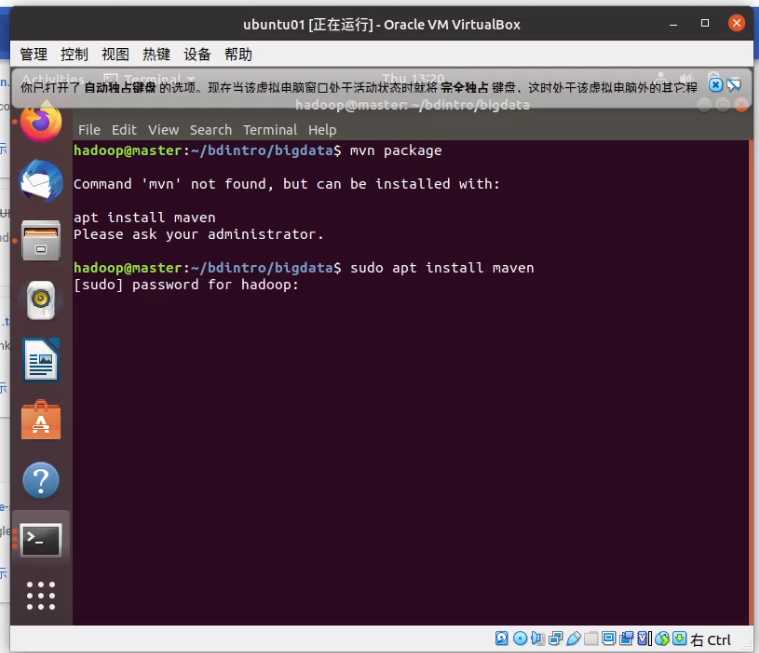
输入密码后,按yes确定安装
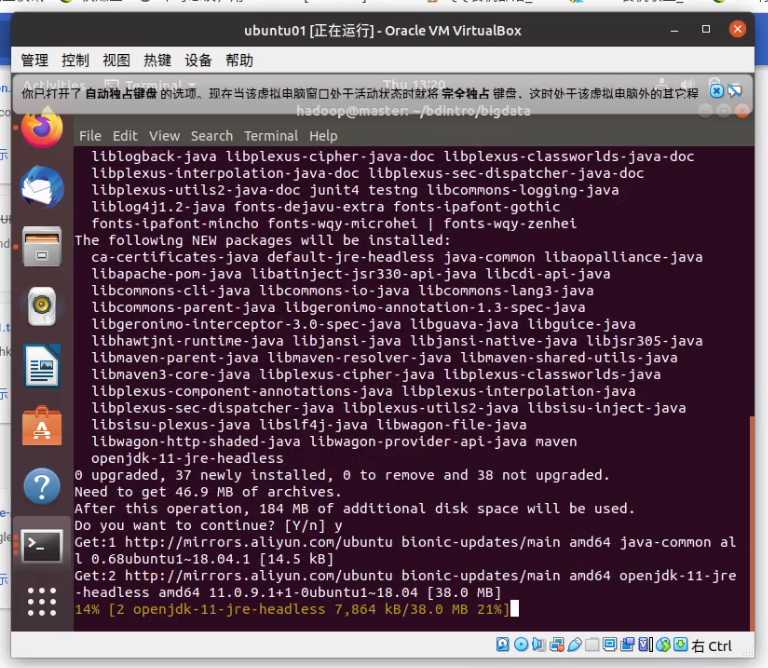
安装完成后,重头戏来了
在 ~/bdintro/bigdata 下打开终端,执行
mvn package
这时就开始滚代码了

不过接下来如果你网络不好的话,会报错
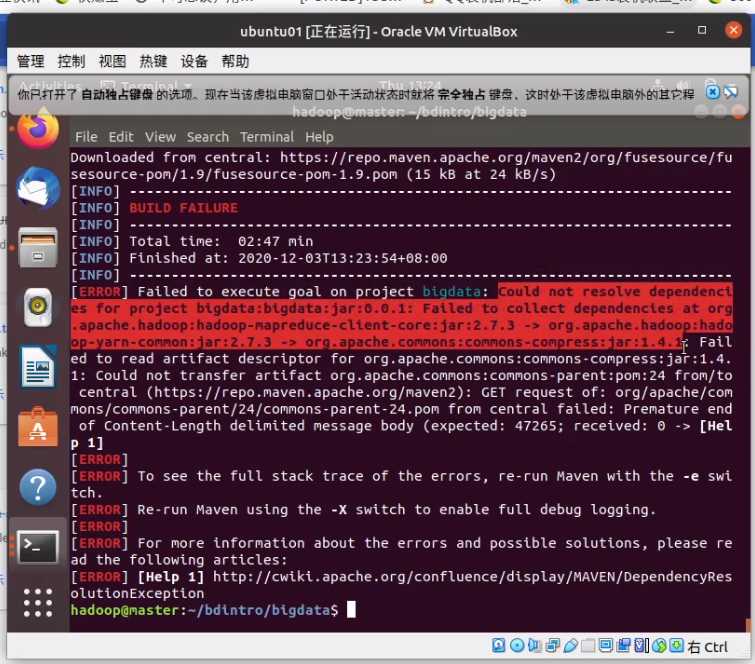
这时你就需要梯子的帮助了,在梯子的buff加成下
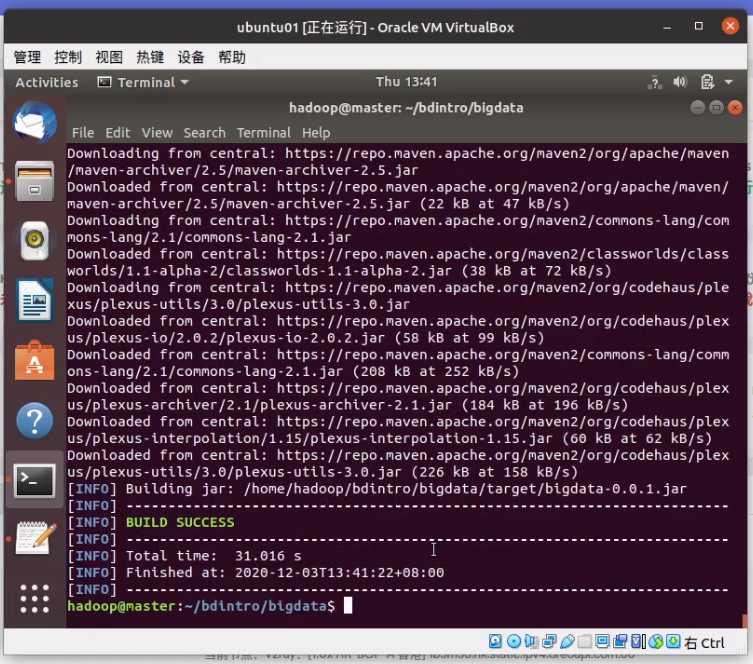
成功后可以在 ~/bdintro/bigdata/target 中得到jar包

3.1.3 做两个实例前的热身
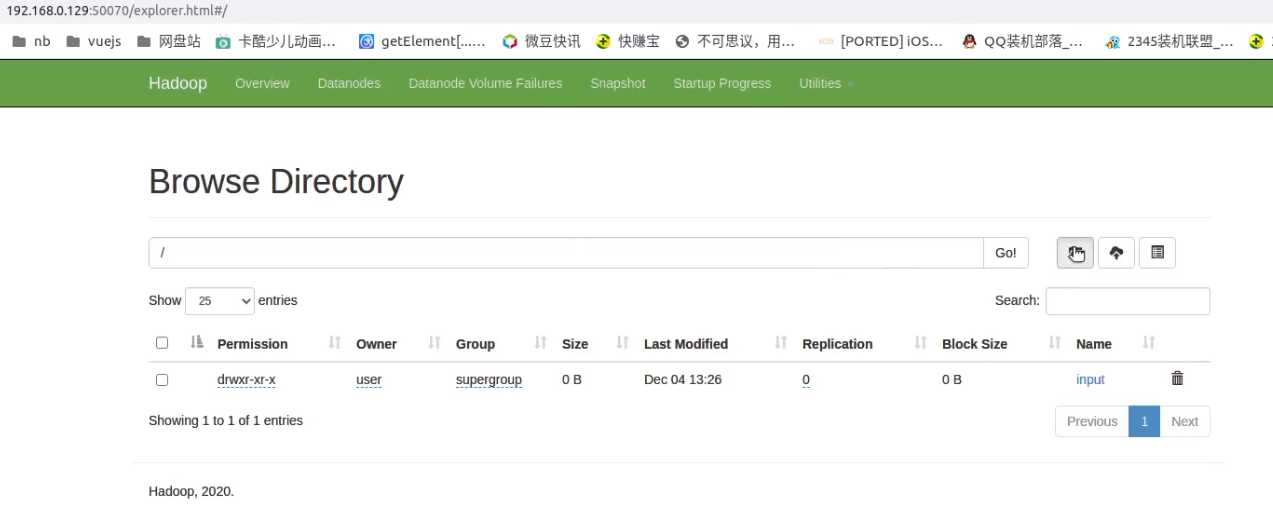
在hdfs文件系统创建input文件夹
hdfs dfs -mkdir /input
浏览器打开你master主机的ip:50070/explorer.html,有显示一个input的文件夹表示创建成功
3.1.4 使用Jar包执行日志分析
把之前下载的 bdintro 的 hadoop-yangyaru-data-node-dell119.log 从 hadoop-yangyaru-data-node-dell119.log.zip 解压出来
上传到hdfs的input文件夹里
hadoop dfs -put hadoop-yangyaru-data-node-dell119.log /input
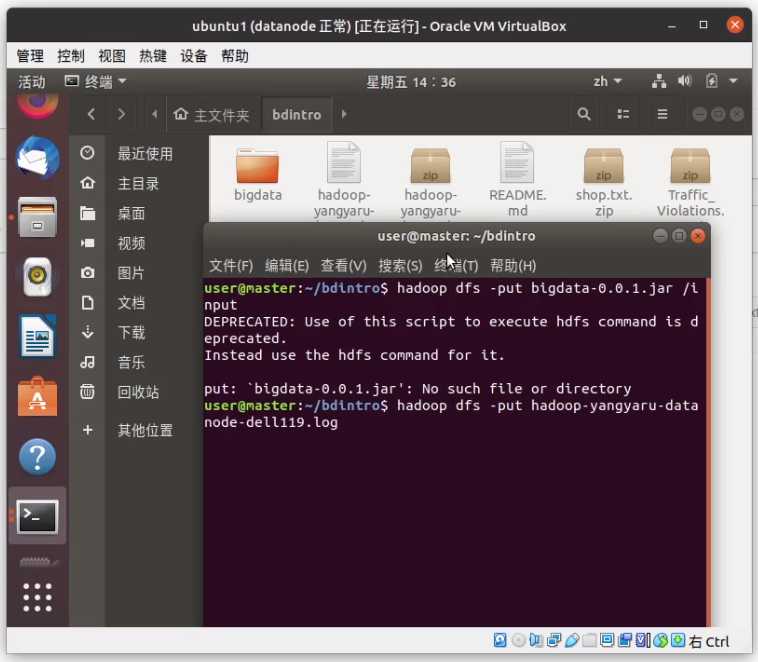
家 目录下创建 jojo.sh 输入以下内容
#!/bin/bash
/usr/hadoop/bin/hdfs dfs -rm -R /output
/usr/hadoop/bin/hadoop jar ~/bigdata-0.0.1.jar \
bigdata.bigdata.Grep \
WARN \
/input/hadoop-yangyaru-datanode-dell119.log \
/output
确保 bigdata-0.0.1.jar 放在家目录下
hadoop-yangyaru-datanode-dell119.log 已经放在 input 文件夹下执行
sh jojo.sh
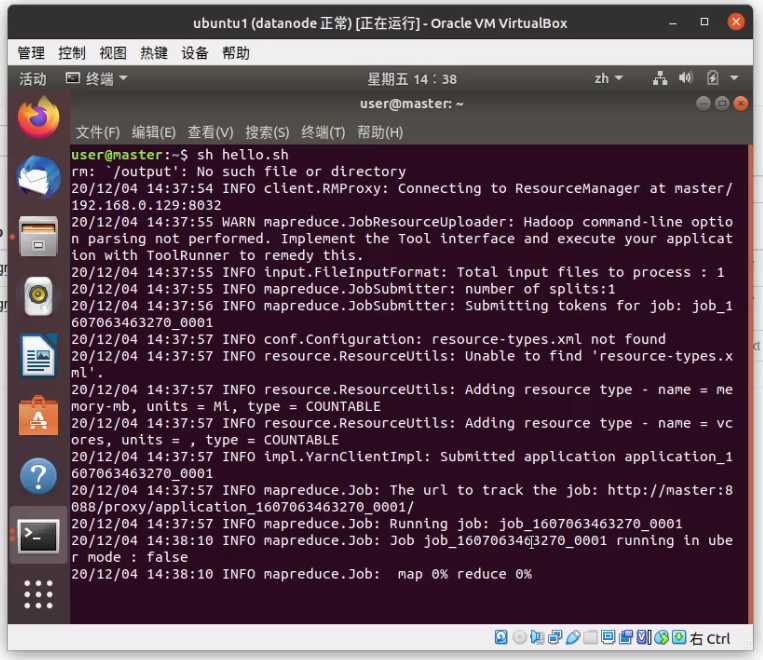
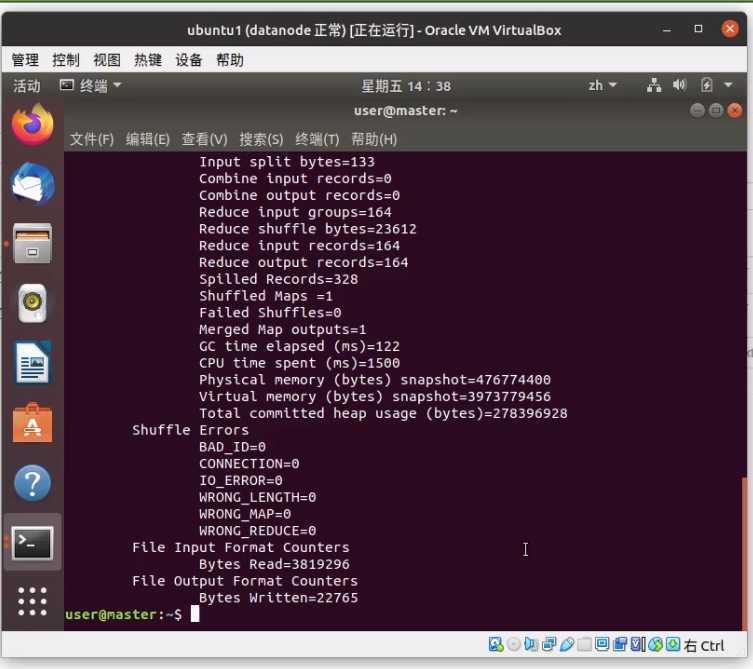
运行完之后打开 ip:50070 会多出两个文件夹
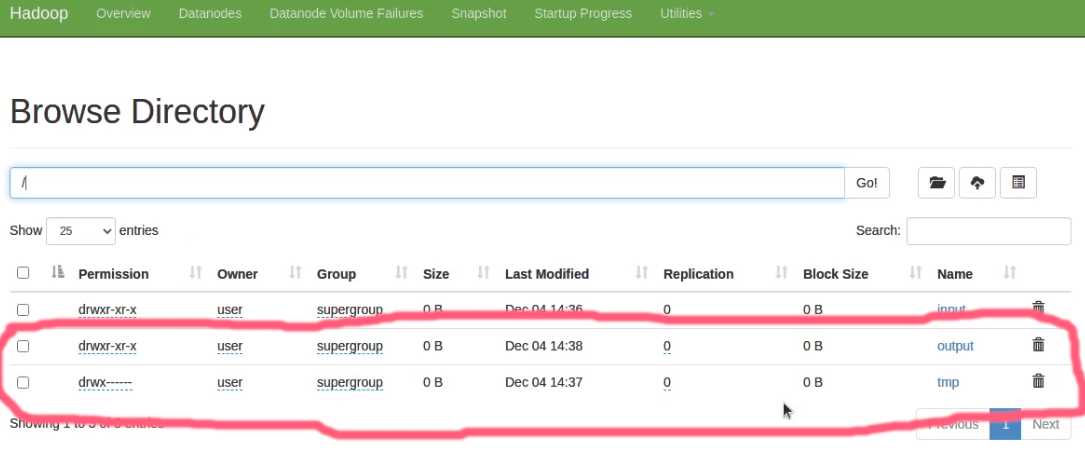
output 文件夹下 有 _SUCCESS即表示成功执行大数据分析,另一个文件就是我们要的结果,直接点击用浏览器下载
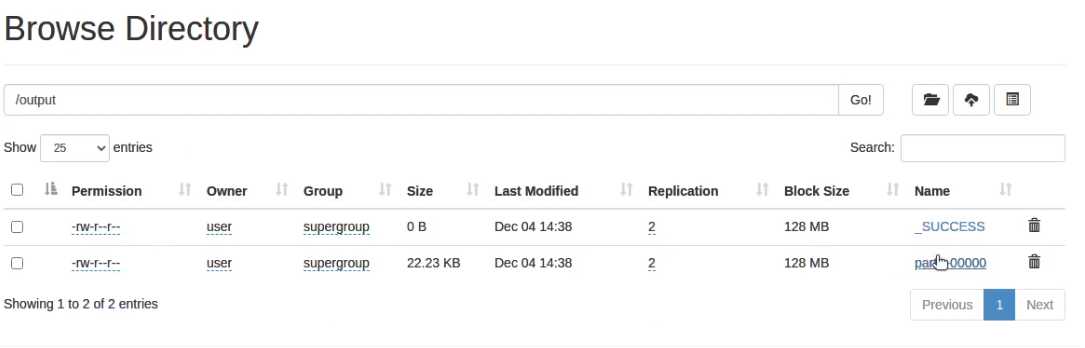
如果用宿主机直接打开的话会没法下载,把 slave1 换成 192.168.0.130 就可以了
part-r-00000 内容
20055 2017-02-24 03:26:50,395 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
22528 2017-02-24 03:27:05,406 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
25001 2017-02-24 03:27:20,416 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
27474 2017-02-24 03:27:35,426 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
29947 2017-02-24 03:27:50,435 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
32420 2017-02-24 03:28:05,448 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
34893 2017-02-24 03:28:20,458 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
37366 2017-02-24 03:28:35,467 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
39839 2017-02-24 03:28:50,476 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
42312 2017-02-24 03:29:05,485 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
44785 2017-02-24 03:29:20,494 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
47258 2017-02-24 03:29:35,504 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
49731 2017-02-24 03:29:50,513 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
52204 2017-02-24 03:30:05,524 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: dell118/10.61.2.118:9000
.....后面省略
3.1.5 交通流量分析
同3.1.4 唯一不同的就是脚本和结果
dio.sh
#!/bin/bash
/usr/hadoop/bin/hdfs dfs -rm -R /output
/usr/hadoop/bin/hadoop jar ~/bigdata-0.0.1.jar \
bigdata.bigdata.TrafficTotal \
/input/hadoop-yangyaru-datanode-dell119.log \
/output
生成结果
01/01/2012 181
01/01/2013 370
01/01/2014 568
01/01/2015 528
01/01/2016 753
01/02/2012 334
....后面省略

Comments | NOTHING